
- December 15, 2022
Degradation is the new Downtime
At AWS:reinvent 2022, we had many excellent conversations with attendees and discovered what enterprises are presently doing with cloud-native technology. Some were using cloud-native exclusively, while the vast majority stated that they were using cloud-native microservices for front-end applications that connect to mainframe infrastructure as the systems of record in a hybrid cloud configuration. In all cases, we asked the attendees if the ever experienced any issues or downtime when using cloud-native technology. To a person, they admitted, YES, either verbally, with a nod of their head, or with an embarrassing acknowledging look. In fact, one attendee went as far as to tell us that “degradation is the new downtime.”
That description confirmed that not only is cloud application downtime problematic, but even performance degradation is a problem facing enterprises. This means that fast mean-time-to-repair is rapidly becoming insufficient. The clear implication is that in order to not only reduce incidents but to also reduce degradation, preventative measures that alleviate issues before they turn into incidents are needed.
Why is Performance Important?
Performance has always been important, but web and application performance came to the forefront in 2009. At that time, Google Research published the following to establish a benchmark for what web and application performance should be.
TUESDAY, JUNE 23, 2009
Posted by Jake Brutlag, Web Search Infrastructure
At Google, we’ve gathered hard data to reinforce our intuition that “speed matters” on the Internet. Google runs experiments on the search results page to understand and improve the search experience. Recently, we conducted some experiments to determine how users react when web search takes longer. We’ve always viewed speed as a competitive advantage, so this research is important to understand the trade-off between speed and other features we might introduce. We wanted to share this information with the public because we hope it will give others greater insight into how important speed can be.
The results of this research become more widely known as the “Google Effect”. It’s impact was to establish a webpage response time of approximately 200 milliseconds as a benchmark for optimum page response time. They further established numerical formulas for determining the negative impact of slower performance.
Technology has progressed significantly since then, especially with cloud and microservices technology, but the underlying principles of performance, resiliency, and availability have remained the same. Performance, resiliency, and availability are critical for cloud stability and efficacy within enterprise.
Source: Google Research
At AWS: reinvent, we were able to speak to those factors by explaining how Instana is the leading Observability platform for preventing issues from turning severe.
What is Real-Time Observability
The key real-time Observability attributes required for Mean Time To Prevention (MTTP) preventative remediation and significantly reduced Mean Time to Repair (MTTR) are:
Real-time (1 second) Telemetry
Full end-to-end traces for all application transactions
AI/ML-driven preventative actions
Time and precision are the critical elements that form the foundation of application and systems availability, resiliency, and performance. Good enough does not apply when it comes to these elements because there’s no real measure that specifies when ‘good enough’ turns into really bad.
Cloud-centric microservices architectures evolved to take advantage of the performance potential of scalable cloud implementations. In theory it is an ideal concept, but in practice it has proven to be fairly complex. Enterprises have found it difficult to determine how to precisely allocate resources when they’re needed and to scale them back when they’re no longer needed. The latter has led to problematic cloud spend overruns.
That’s why Observability platforms emerged to manage complex elastic cloud-native applications and handle cloud applications at scale. To accomplish that, it’s become clear conditions change in the cloud rapidly and that precision observability measurements are necessary to not only prevent downtime but to also preempt degradation. The Google Effect has not only persisted, but also extended to applications of all types. Users have and are likely to continue having low tolerance for degraded performance.
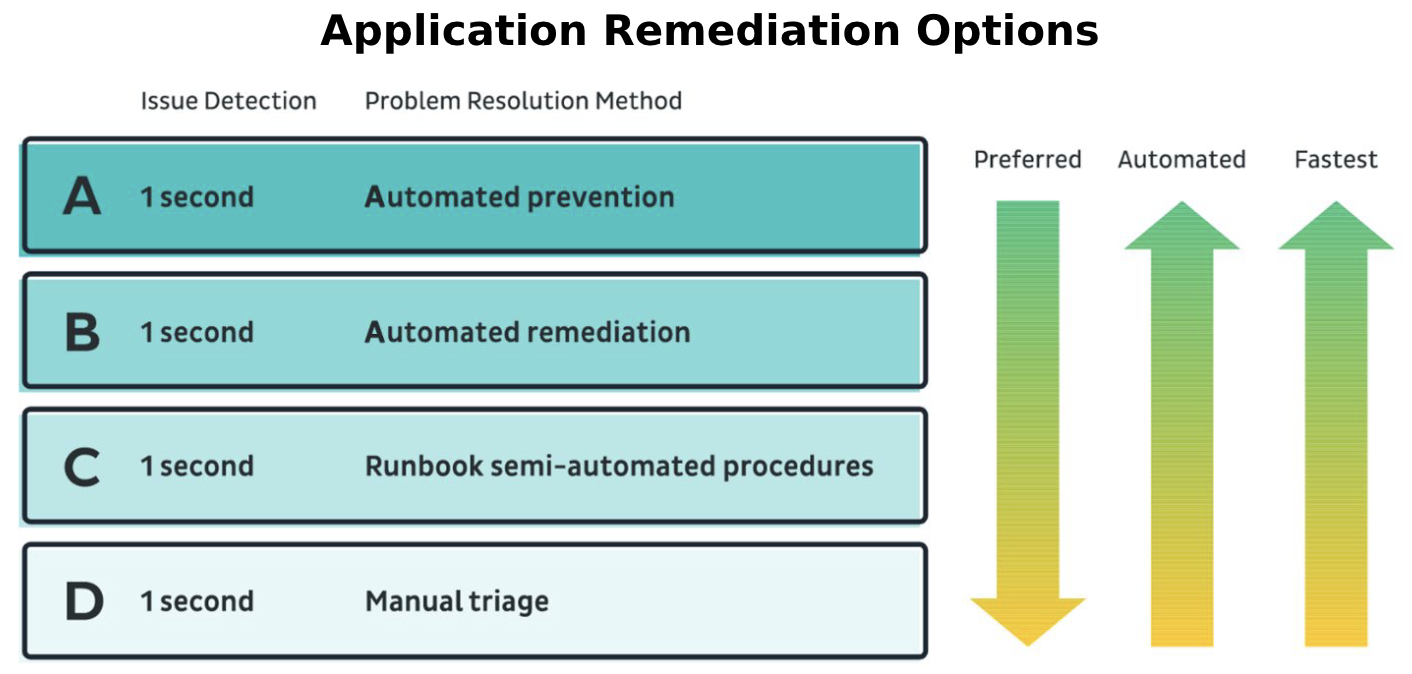
Instana designed its real-time Observability platform to provide precise one second metrics, full end-to-end traces, and AI-driven context to ensure the fastest discovery of issues and the ability to provide remediation before they turn into incidents.
Instana is the only Observability platform that can make rapid remediation happen by instantly discovering issues. It can be used to avert issue escalation by using AI and to AIOps for preventative measures (MTTP). It also can enable faster MTTR when issues require manual remediation. Waiting 5 minutes for metrics and sampled traces do not and cannot provide rapid issue prevention and delays MTTR.
The options listed in the Application Remediation Options image above specify a range of remediation types – from fully automated Application Resource Management (ARM) to semi-automated and manual repair (MTTR). IBM Turbonomic ARM and AWS Compute and Cost Optimizer are examples of ARM remediation tools that can also be used to optimize cloud costs.
Because performance degradation is the new downtime, manual software repair methods alone does not suffice to reduce degradation. Only Real-Time Observability combined with automated ARM can not only help remediate degradation but also help prevent issues from turning into downtime incidents.
SOURCE:
https://www.instana.com/blog/degradation-is-the-new-downtime/



